
Computer Vision
Our computer vision team is a leader in the creation of cutting-edge algorithms and software for automated image and video analysis. Our solutions embrace deep learning and add measurable value to government agencies, commercial organizations, and academic institutions worldwide. We understand the difficulties in extracting, interpreting, and utilizing information across images, video, metadata, and text, and we recognize the need for robust, affordable solutions. We seek to advance the fields of computer vision and deep learning through research and development and through collaborative projects that build on our open source software platform, the Kitware Image and Video Exploitation and Retrieval (KWIVER) toolkit.
Our customers include the Defense Advanced Research Project Agency (DARPA), the Intelligence Advanced Research Projects Activity (IARPA), the Air Force Research Laboratory (AFRL), and the Office of Naval Research (ONR). We have worked with these agencies to deploy an operational Wide Area Motion Imagery (WAMI) tracking system for Intelligence, Surveillance, and Reconnaissance (ISR) in theater and to develop advanced sensor exploitation capabilities that focus on the fusion of sensors, platforms, and people. We have also worked with small and large private companies such as Lockheed Martin and Raytheon through customized software R&D projects.
Headlines and Beyond
Areas of Focus
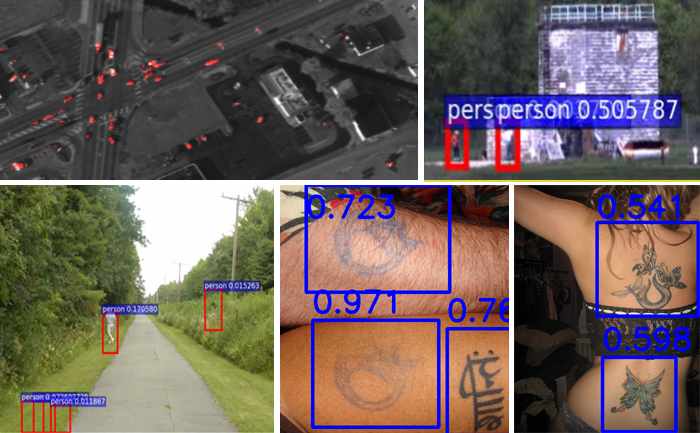
Deep Learning
Through our early adoption of deep learning over the past few years, we have demonstrated dramatic improvements in object detection, recognition, semantic segmentation, and content based retrieval. In doing so, we have addressed different customer domains with unique data as well as operational challenges and needs. Our expertise focuses on hard visual problems such as low resolution, very small training sets, large data volumes, and real-time processing. Each of these requires us to creatively utilize and expand upon deep learning, which we apply to our other computer vision areas of focus to deliver more innovative solutions.
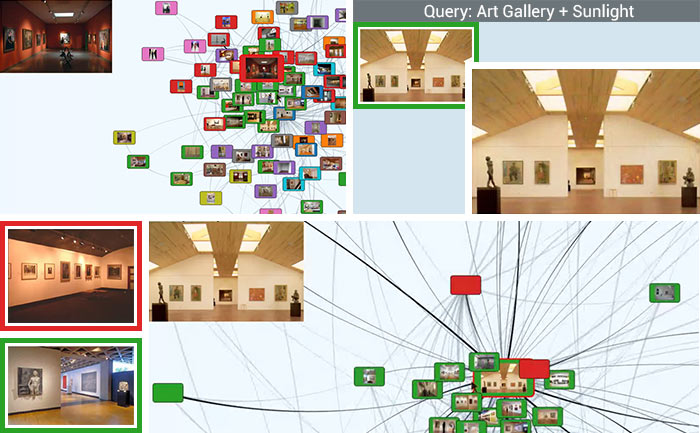
Social Multimedia Analysis
Released as open source software in the Social Multimedia Query Toolkit (SMQTK), our large-scale multimedia analysis tools can automatically understand content from millions of videos and images on social media. This toolkit incorporates our expertise in object detection, scene understanding, event recognition, knowledge discovery, and interactive query refined to provide accurate, fast, content-based search capabilities that are visualized in web-based graphical user interfaces. These tools provide new capabilities to mine and translate vast amounts of unlabeled and unstructured data into salient information for real-world applications.
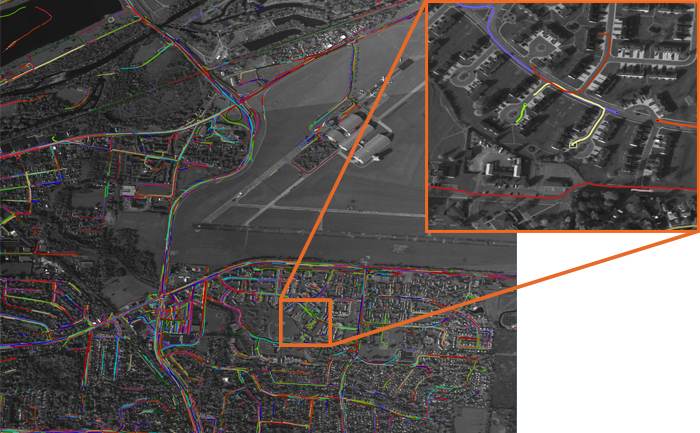
Object Detection and Tracking
Our video object detection and tracking tools are the culmination of years of continuous government investment totaling millions of dollars. Deployed operationally in limited experiments, our suite of trackers can identify and track moving objects in all types of ISR video such as WAMI and aerial Full Motion Video (FMV) from diverse platforms. They address difficult scenarios like low contrast, moving cameras, occlusions, shadows, and high traffic density through multi-frame track initialization, track linking, reverse-time tracking, and other techniques. These tools make it possible to perform tasks, which include among others ground camera tracking in congested scenes; real-time multi-target tracking in full-field WAMI; and tracking people in low-resolution, low-quality video.
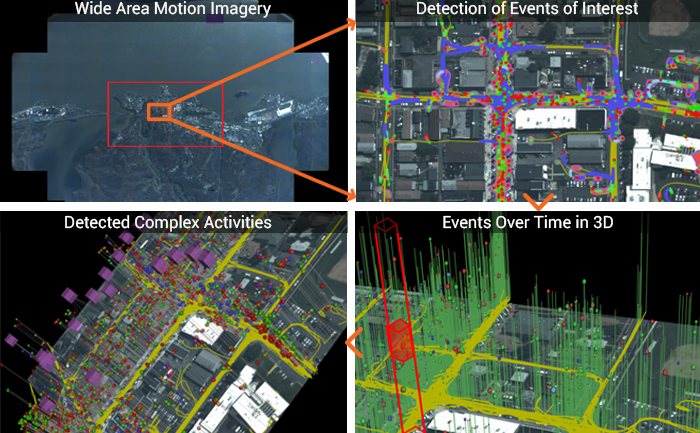
Complex Activity, Event, and Threat Detection
Our tools recognize high-value events, salient behaviors, and complex activities and threats through the interaction and fusion of low-level actions and events in dense cluttered environments. Operating on tracks from WAMI, FMV, MTI or other sources, these algorithms characterize, model, and detect actions, such as people carrying objects and vehicles starting/stopping, along with complex threat indicators such as people transferring between vehicles and multiple vehicles meeting. Our capabilities include highly efficient search through huge data volumes, such as full-frame WAMI missions, using approximate matching to detect threats despite missing data, detection errors and deception.
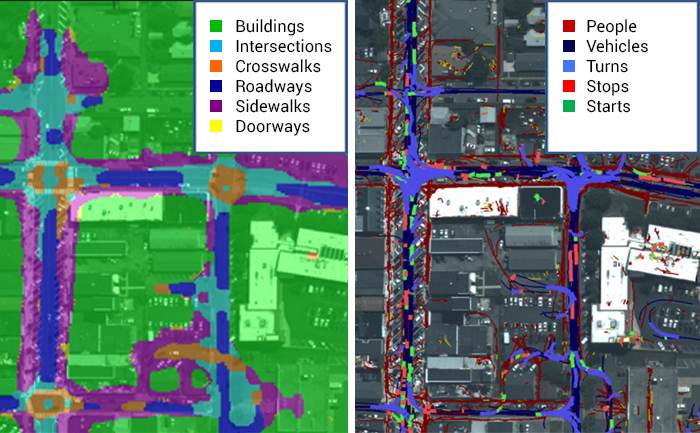
Image and Video Scene Understanding
In single images or video frames, our knowledge-driven scene understanding capabilities use deep learning techniques to segment any scene into a large number of semantic object types with high accuracy. In video, our unique approach defines objects by behavior rather than appearance. Through observing mover activity, our capabilities can segment a scene into functional object categories like roadways, sidewalks, intersections, doorways, gates, and mailboxes, which may not be distinguishable by appearance alone. These capabilities are unsupervised so they automatically learn new functional categories without any manual annotations. While scene understanding is useful on its own, it significantly improves threat detection, anomaly detection, 3D reconstruction, and other vision capabilities.

3D Vision
Our 3D vision capabilities can estimate camera models, 3D point clouds, and dense 3D surfaces from multi-view imagery or video, without requiring any metadata or calibration information. Our algorithms can also analyze 3D point cloud data from video, lidar, and other depth sensors to register multiple scans and detect objects. We conduct ongoing research to jointly reason about scene semantics and 3D reconstruction to maximize the accuracy of object classification and 3D shape. Released as open source software, the Motion-imagery Aerial Photogrammetry Toolkit (TeleSculptor) is continuously evolving to create new ways to automatically analyze, visualize, and make measurements from images and video. We leverage such tools to build standard desktop and mobile applications.

Image and Video Forensics
In the new age of disinformation, it has become critical to validate the integrity of images. As photo-manipulation software and techniques are evolving, we are developing capabilities to automatically detect image and video editing by exploiting the physical plausibility of reflections in images and kinematic continuity in videos. As they mature, these capabilities will assess large archives to efficiently identify media that may have been manipulated.

Super Resolution
Our super-resolution techniques combine multiple aerial or satellite images with prior knowledge to produce high-resolution images. To do so, they use novel methods to compensate for widely spaced views and illumination changes, which are the two primary challenges that plague super-resolution algorithms. The output images can be used for improved manual exploitation or for input to algorithms in object detection and 3D reconstruction, among other applications. Higher-resolution images enhance detail, enable exploitation that is not possible on lower-resolution images, and improve downstream automated analytics such as the detection of static objects.
What We Offer for Your Project

We provide custom research and software development, collaboration, support, training, and books to help in the above areas of focus.
Publications
We have around 200 publications in journals, conference proceedings, etc., on topics such as convolutional neural networks, deep learning, image and video analytics, and situational awareness.
Computer Vision Platform

The Kitware Image and Video Exploitation and Retrieval (KWIVER) toolkit is an open source, production-quality image and video exploitation platform. It comes with unrestricted licensing to engage the full-spectrum video research and development (R&D) community, including academic, industry, and government organizations. KWIVER provides advanced capabilities in 3D reconstruction from aerial video, social multimedia indexing and retrieval, and video object tracking and super-resolution. In addition, it provides supporting tools for quantitative evaluation, pipeline processing, software builds, and more.